Pour la plupart des organisations, la collecte et l'analyse rapides des données sont cruciales pour rationaliser les opérations, assurer la sécurité et obtenir des informations IT et OT en temps opportun. Le calcul rapide et la gestion des données sont également d'une importance cruciale pour l'industrie 4.0, l'automatisation de la fabrication, les véhicules autonomes et d'autres applications à forte intensité de données. Les solutions d'Edge computing disponibles aujourd'hui permettent aux organisations de capitaliser sur l'Internet des objets (IoT) en déployant des dispositifs intelligents à la périphérie du réseau pour réduire la latence et l'utilisation de la bande passante en gérant les données là où elles sont générées.
Qu'est-ce que l'informatique de périphérie ?
L'informatique en périphérie est une architecture qui utilise un modèle informatique distribué pour éliminer les inefficacités de la gestion des données et réduire les temps de latence. IoT et les appareils mobiles dans le cadre distribué utilisent des appareils IoT tels que des systèmes intégrés, des routeurs cellulaires et des serveurs en série pour collecter et traiter les données à la source au lieu de les transférer vers un serveur central, un centre de données ou une solution en nuage pour le traitement, comme cela serait nécessaire avec une approche traditionnelle de l'informatique en nuage et de la gestion des données sur IoT .
Le modèle d'informatique périphérique permet aux entreprises d'économiser de la bande passante, du temps et de l'argent. Ce modèle exploite la puissance des appareils de périphérie intelligents, l'intelligence de périphérie et la connectivité cellulaire comme moyen de réduire le trafic inter-réseaux et d'améliorer l'efficacité. L'intelligence artificielle (AI) et l'apprentissage automatique (ML) peuvent accélérer la vitesse de traitement de l'architectureIoT en effectuant des analyses en périphérie, en identifiant des modèles, en prenant des mesures et en acheminant des données.

IoT et Edge Computing
IoT se réfère à une variété de dispositifs de collecte de données, qui peuvent ou non traiter les données à la périphérie. Voici quelques exemples de dispositifs IoT :
- Moniteurs de production manufacturière
- Produits de santé portables
- Détecteurs de mouvement de sécurité
- Systèmes d'éclairage intelligents
- Véhicules autopilotés
- Contrôles intelligents des feux de circulation
- Capteurs de surveillance de l'environnement
- Compteurs intelligents
- Dispositifs de suivi du parc automobile
L'informatique de pointe dans IoT permet aux appareils d'augmenter l'efficacité de l'utilisation des données et de rationaliser les opérations. Associés à la technologie Edge Computing, les appareils IoT peuvent prendre en charge le traitement des données en temps réel afin d'améliorer les vitesses d'acheminement des données dans les applications critiques, d'assurer une meilleure gestion de la bande passante et de réduire les coûts liés aux données.
Comment fonctionne l'informatique en périphérie ?
Les solutions d'informatique périphérique soutiennent une série d'objectifs opérationnels. L'infrastructure périphérique peut comprendre des caméras, des capteurs et toute une série de dispositifs IoT qui effectuent un traitement immédiat et local et n'acheminent que des données spécifiques vers des serveurs centralisés en vue d'une analyse plus poussée, d'une vision opérationnelle ou d'un stockage. Les dispositifs intelligents de périphérie peuvent également prendre un certain nombre de mesures, qu'il s'agisse d'effectuer des analyses, de lancer des rapports ou des tickets de service, ou de provoquer immédiatement l'arrêt de machines ou d'opérations en raison de problèmes de sécurité.
Après le traitement initial, les dispositifs informatiques périphériques déterminent quelles données doivent être transférées à d'autres systèmes. Par conséquent, la quantité de données envoyées sur le réseau est limitée, ce qui garantit que seules les informations critiques sont transmises aux centres de données ou aux solutions en nuage pour l'intelligence économique. Pour mettre en œuvre ce paradigme sophistiqué de l'informatique en périphérie, il faut une combinaison de puces informatiques spécialisées, de capacités de traitement des appareils et d'outils de surveillance et de gestion à distance.
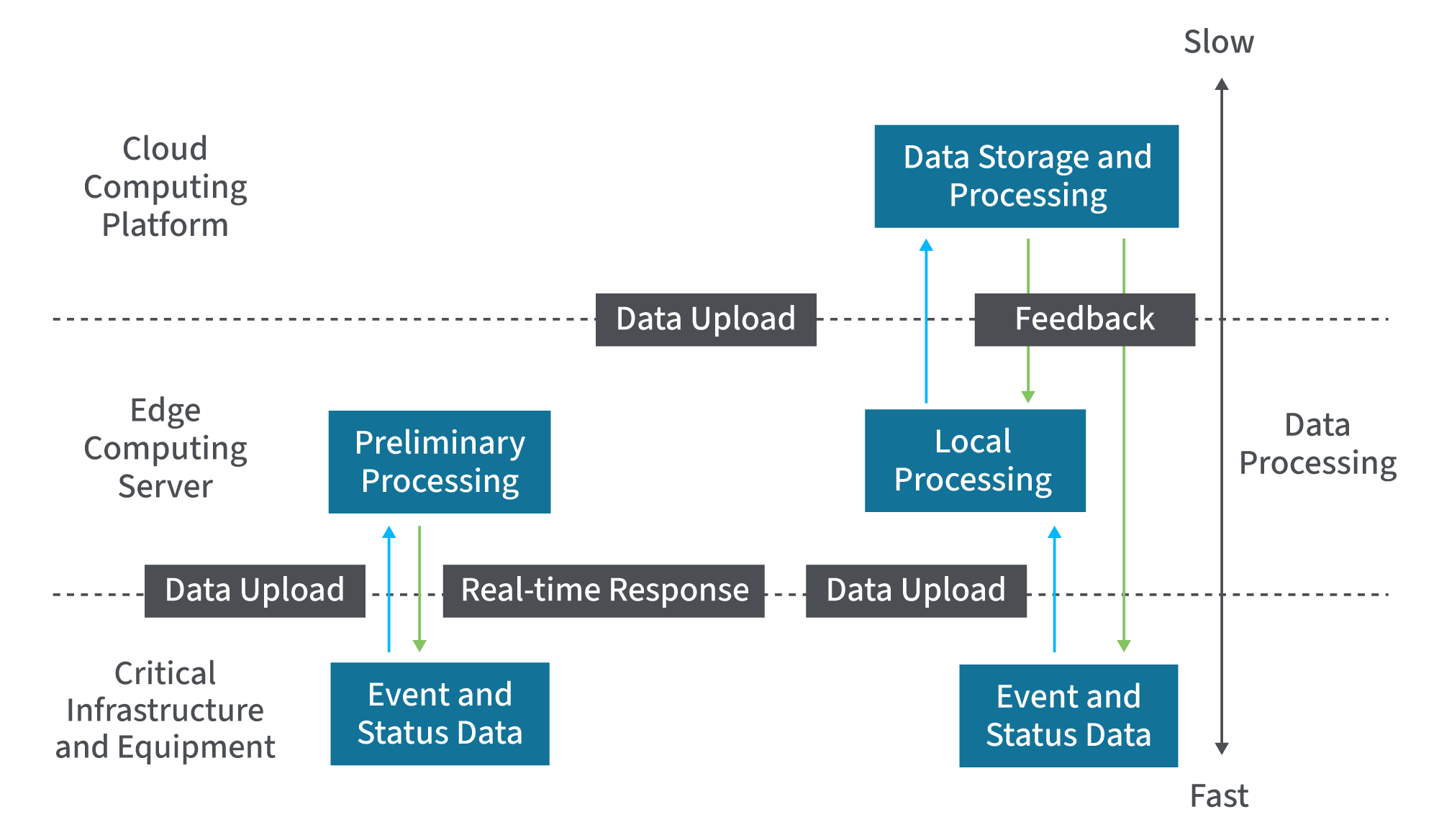
Traitement des bords
Les approches traditionnelles de l'analyse des données reposent généralement sur des solutions de traitement centralisées, telles que les centres de données, les solutions en nuage ou les serveurs. Bien que ces méthodes offrent une puissance de calcul suffisante, elles nécessitent l'envoi de données à partir de dispositifs IoT ou d'autres points de collecte à travers le réseau pour le traitement. En fin de compte, cela entraîne une latence et nécessite une bande passante importante, ce qui se traduit par une efficacité moindre.
Dans le cadre d'un déploiement en périphérie, les appareils mobiles, IoT et autres appareils informatiques en périphérie disposent de capacités de traitement pour analyser les informations collectées et favoriser l'automatisation, la prise de décision en temps réel ou les ajustements opérationnels. Pour ce faire, on utilise des puces intégrées et des appareils intelligents en périphérie, ce qui permet un traitement immédiat en périphérie, là où les données sont générées.
Les avantages de l'informatique en périphérie, comparés à ceux de l'informatique en nuage, sont également considérables. Dans le cas de l'informatique en nuage, il existe une couche de traitement entre la couche périphérique et le centre de données central ou la solution en nuage. Bien que ces serveurs contribuent au traitement, ils nécessitent toujours la transmission de données à partir du point de collecte, ce qui peut utiliser une bande passante importante et entraîner des temps de latence. L'informatique distribuée en périphérie permet à chaque dispositif en périphérie du réseau de collecter, de stocker et de traiter les données de manière autonome. Une connexion constante au réseau n'est souvent pas nécessaire, ce qui permet aux opérations de se poursuivre quelle que soit la stabilité de la connexion.
Infrastructure périphérique
L'infrastructure périphérique englobe tous les composants du réseau, les appareils mobiles connectés et les points d'accès IoT au sein d'un système plus large. Les solutions matérielles et logicielles exactes en matière d'informatique périphérique varient et peuvent inclure une série de nœuds et de dispositifs informatiques périphériques :
Il y a également une composante logicielle à prendre en compte. Par exemple, des plateformes comme Digi Remote Manager® permettent aux organisations de surveiller et de contrôler le matériel à la périphérie, ce qui en fait un élément nécessaire de l'équation.
Par exemple, Digi Remote Manager offre une visibilité à l'échelle du réseau, un accès à distance, une configuration des appareils et une surveillance de la sécurité à partir d'un "panneau de verre unique". En outre, cette solution fournit des alertes et des notifications instantanées à partir de la périphérie du réseau, sur la base de conditions spécifiques, et permet un accès hors bande aux dispositifs de périphérie pour la gestion à distance.
Avantages de l'informatique en périphérie
L'informatique en périphérie présente de nombreux avantages qui rendent cette approche intéressante pour un large éventail de cas d'utilisation. En voici quelques exemples :
- Avec IoT edge computing, les entreprises industrielles peuvent surveiller activement la production, ce qui leur permet de prendre des décisions opérationnelles basées sur des données en temps réel.
- Et dans les applications de l'industrie 4.0, l'edge computing est crucial pour le traitement en temps réel dans la robotique et l'automatisation de la fabrication.
- Le traitement des données en temps réel permet d'intervenir immédiatement dans le domaine de la santé lorsque l'état d'un patient évolue, et permet aux sociétés financières de tirer parti de l'évolution rapide des conditions du marché.
- Les outils d'informatique périphérique et les dispositifs intelligents permettent aux entreprises de tous les secteurs de réduire la charge du réseau et l'utilisation de la bande passante. Outre les économies réalisées, cela réduit l'exposition aux menaces potentielles. En outre, les opérations critiques peuvent se poursuivre même en cas de perte de connexion au cloud, ce qui permet aux applications et aux systèmes d'informatique de pointe d'assurer la continuité des activités.
Voici un examen plus approfondi de certains des avantages des plateformes, des logiciels, des services et de l'infrastructure de l'informatique de pointe :
- Analyse des données en temps réel: Les logiciels et solutions d'informatique de pointe éliminent les retards de traitement. Les entreprises peuvent ainsi obtenir des informations immédiates, ce qui leur permet de prendre des décisions en temps réel pour améliorer l'efficacité, résoudre rapidement les problèmes ou tirer parti de brèves périodes d'opportunité.
- Sécurité et protection de la vie privée: Le traitement en périphérie nécessitant moins de transmission d'informations sur les réseaux, l'exposition aux menaces est minimisée, car les données sensibles n'ont jamais besoin de traverser l'internet. En outre, une grande partie des données n'est pas stockée chez un fournisseur tiers de services en nuage.
- Bande passante et efficacité: Comme les services d'informatique de périphérie effectuent le calcul, l'analyse et l'automatisation à la périphérie, ils réduisent l'utilisation des ressources du réseau et de la bande passante et augmentent l'efficacité. En outre, l'utilisation réduite de la bande passante se traduit souvent par des économies, ce qui permet aux entreprises de réduire les appels de service ou d'éviter les dépassements inattendus susceptibles d'entraîner des frais supplémentaires.
- Vitesse et réduction des temps de latence: L'informatique en périphérie permet de réagir plus rapidement aux événements locaux. Avec l'informatique en périphérie, le temps de latence peut généralement être réduit à près de zéro. Outre les avantages directs pour les organisations, la vitesse offre une meilleure expérience pour les applications centrées sur l'utilisateur, telles que les jeux, la diffusion en continu et les communications en temps réel.
- Gestion à distance: Les plateformes de gestion à distance permettent aux organisations de superviser à distance les appareils périphériques déployés, ce qui simplifie la gestion des appareils et du réseau. Ces plateformes centralisées sont un élément essentiel de l'équation, car elles garantissent l'accessibilité, les informations et les notifications depuis n'importe quel endroit via un ordinateur de bureau ou un appareil mobile.
- Évolutivité: Le déploiement d'une infrastructure périphérique favorise l'expansion des dispositifs déployés et l'évolutivité globale, ce qui permet aux entreprises d'augmenter ou d'ajouter des fonctionnalités en cas de besoin et aux systèmes informatiques périphériques de gérer des charges de données croissantes provenant d'un nombre de plus en plus important de dispositifs connectés.
- Maîtrise des coûts: L'informatique en périphérie peut aider les entreprises à réduire leurs coûts en diminuant le besoin d'une infrastructure en nuage étendue. En outre, le traitement et le stockage localisés peuvent être plus rentables, en particulier pour les organisations opérant dans des environnements où les ressources sont limitées.
- Durabilité: Grâce à l'informatique en périphérie, les entreprises peuvent réduire leur empreinte carbone et améliorer le développement durable. Les dispositifs de périphérie sont souvent alimentés par des batteries à faible consommation d'énergie. La prise de décision en temps réel qu'ils permettent peut également éliminer le gaspillage en identifiant les inefficacités ou en ajustant les processus, et la capacité d'augmenter ou de réduire rapidement la taille des opérations peut les maintenir continuellement à la bonne taille, garantissant une utilisation efficace de l'énergie et des ressources.
- L'IA à la périphérie: L'intégration de l'IA dans les produits et solutions d'informatique périphérique améliore les capacités des appareils IoT . Des capacités avancées de traitement et d'analyse des données sont disponibles au niveau de l'appareil, ce qui permet d'obtenir des informations plus puissantes, souvent en temps réel.
Solutions d'informatique de pointe
Pour une solution efficace, les entreprises doivent adapter leur infrastructure de pointe à leur secteur d'activité et à leur cas d'utilisation. Cela permet de s'assurer que la solution répondra aux besoins uniques, aux priorités et aux points problématiques avec une approche ciblée.
Les solutions complètes d'informatique de périphérie permettent également aux entreprises d'exploiter les technologies de pointe pour améliorer leurs résultats. L'intégration de la connectivité cellulaire 5G réduit la latence et améliore la connectivité des périphériques sur le réseau. La mise en œuvre de l'IA et de l'apprentissage automatique peut permettre un traitement avancé des données en temps réel au niveau de l'appareil, favorisant la vitesse et l'agilité lorsque c'est le plus important.
Informatique d'entreprise en périphérie (Edge Computing)
L'informatique d'entreprise traditionnelle repose largement sur la transmission de données, les données étant créées à des points finaux tels que les ordinateurs des utilisateurs avant d'être transférées vers des serveurs centralisés. L'informatique d'entreprise en périphérie utilise la puissance de calcul des appareils sur le réseau, ce qui réduit la pression sur les ressources du réseau, diminue les coûts des données, améliore la fiabilité et augmente la vitesse.
Grâce à des solutions d'informatique de pointe sur mesure, les entreprises peuvent créer un écosystème personnalisé pour favoriser l'évolutivité et maintenir un prix abordable tout en améliorant l'efficacité.
Informatique industrielle de pointe
L'informatique de périphérie industrielle fournit aux dispositifs de périphérie, aux systèmes d'automatisation, aux machines et à la robotique la puissance de traitement à grande vitesse dont ils ont besoin et permet aux organisations d'accéder à des analyses en temps réel qui favorisent une prise de décision rapide dans des environnements en constante évolution. Les dispositifs IIoT Edge (Internet industriel des objets) conçus pour ce secteur sont généralement robustes - ce qui garantit qu'ils peuvent résister à des défis environnementaux tels que des températures extrêmes et continuer à fonctionner de manière optimale - et ont une grande fiabilité avec un basculement et une redondance intégrés.

Applications et cas d'utilisation de l'informatique en périphérie
Aujourd'hui, les applications d'informatique de pointe sont déjà utilisées tout autour de nous, des lecteurs d'empreintes digitales sur les smartphones à la surveillance du trafic en temps réel aux carrefours. Examinons quelques exemples d'informatique de pointe dans différents secteurs d'activité.
Fabrication
Dans le secteur manufacturier, les solutions d'informatique de périphérie permettent l'automatisation de la fabrication, la robotique et la maintenance prédictive. IoT les appareils de périphérie dans le paradigme de l'industrie 4.0 peuvent effectuer des assemblages en usine, augmenter ou réduire rapidement la production en fonction de la demande et améliorer la vitesse et la précision de la production - libérant ainsi le personnel pour qu'il s'occupe des tâches d'ingénierie, de technicien et de gestion.
En outre, les caméras vidéo et les dispositifs de pointe IoT peuvent détecter les anomalies dans la production et retirer les pièces qui ne sont pas conformes aux spécifications. Ils peuvent surveiller l'efficacité de la production et comparer les données à des calendriers historiques pour faciliter les réparations proactives. Et ils peuvent utiliser des diagnostics adaptatifs pour alerter les techniciens sur la source potentielle des problèmes afin d'accélérer le dépannage. IoT et l'informatique de pointe sont aujourd'hui à l'origine d'une transformation numérique complète de l'industrie manufacturière, permettant aux fabricants de construire des usines intelligentes, en utilisant des dispositifs de pointe pour soutenir l'automatisation industrielle et la maintenance prédictive.
Vente au détail
Dans le secteur de la vente au détail, le traitement des données en périphérie soutient l'analyse en temps réel en magasin, permettant aux détaillants de s'adapter rapidement à des conditions changeantes. IoT peut automatiser la gestion des stocks, en alertant les détaillants lorsque les quantités de produits spécifiques tombent en dessous des seuils fixés. L'informatique de périphérie peut également personnaliser les expériences d'achat pour les clients, en utilisant des informations basées sur des données pour personnaliser les recommandations aux clients et faire des ajustements de prix dynamiques pour augmenter les ventes de produits et de services.
Soins de santé
L'informatique périphérique permet le traitement en temps réel des données générées par les dispositifs médicaux, les objets portés sur soi et les capteurs. Cet aspect est crucial dans les scénarios de soins de santé nécessitant des décisions et des réponses immédiates, tels que des changements soudains dans les signes vitaux des patients ou des situations médicales d'urgence.
Les dispositifs médicaux portables peuvent stocker des informations sur le rythme cardiaque, la température, la glycémie et d'autres mesures qui peuvent ensuite envoyer des notifications importantes au patient ou au médecin et fournir des rappels intelligents pour la prise de médicaments. En outre, l'informatique de pointe permet aux organismes de santé d'améliorer la sécurité et la confidentialité en limitant la transmission d'informations sensibles et protégées sur les patients. L'informatique de pointe peut également renforcer les capacités des solutions de télémédecine, et les appareils IoT peuvent effectuer une analyse rapide des données pendant les procédures médicales critiques, améliorant ainsi l'expérience et les résultats pour les patients.
Transport
L'informatique de pointe joue un rôle crucial dans la transformation des systèmes de transport, offrant diverses utilisations et avantages pour améliorer l'efficacité, la sécurité et les performances globales. Voici quelques applications et avantages clés de l'informatique de pointe dans les transports :
- Véhicules autonomes: L'informatique de pointe permet aux véhicules autonomes d' analyser les données en temps réel et de prendre des mesures rapides pour s'adapter aux conditions changeantes, lire les panneaux de signalisation et les feux de circulation et y réagir, et maintenir la sécurité.
- Gestion du trafic en temps réel et acheminement des transports en commun: IoT et l'informatique de pointe permettent aux villes intelligentes de gérer le trafic de manière proactive en adaptant les feux de circulation à l'évolution des conditions sur les routes. Aujourd'hui, le traitement des signaux de transport en commun permet aux bus de naviguer de manière plus fluide dans les rues encombrées de la ville afin de garantir que les passagers des transports en commun arrivent à destination à l'heure.
- Véhicules d'urgence: Grâce à des routeurs cellulaires embarqués sophistiqués, les véhicules de police tirent de plus en plus parti du traitement en périphérie pour gérer localement les données provenant des appareils et périphériques embarqués, ainsi que des caméras et appareils de communication portés sur le corps, afin d'améliorer les délais d'intervention.
- Logistique: Les organisations d'expédition et de réception bénéficient de IoT et de l'informatique de pointe pour le suivi des actifs et la surveillance des véhicules et des cargaisons.
Villes intelligentes
Grâce à l'informatique de pointe, les villes intelligentes d 'aujourd'hui peuvent améliorer la durabilité en gérant de manière proactive l'utilisation de l'énergie dans les infrastructures, y compris les services publics, l'éclairage urbain, la gestion de l'eau et des eaux usées et les systèmes de mobilité urbaine. De même, les solutions de périphérie peuvent permettre aux organismes de sécurité publique de rester connectés, garantissant ainsi la disponibilité de données en temps réel en cas d'urgence, y compris lors de catastrophes naturelles. IoT et l'informatique de périphérie soutiennent également la gestion des déchets, le compactage des ordures et l'acheminement intelligent des véhicules d'assainissement. En outre, les dispositifs IoT permettent aux villes de surveiller les bâtiments et les véhicules appartenant à l'État, ce qui améliore la sécurité et garantit une utilisation correcte.
Technologie de l'informatique de pointe
La technologie de l'informatique de périphérie réunit la puissance des réseaux plus rapides, des dispositifs de périphérie intelligents et des améliorations de la programmation, ce qui permet aux calculs et à la gestion des données de se produire à la périphérie du réseau. Examinons les composants d'un modèle d'informatique périphérique.
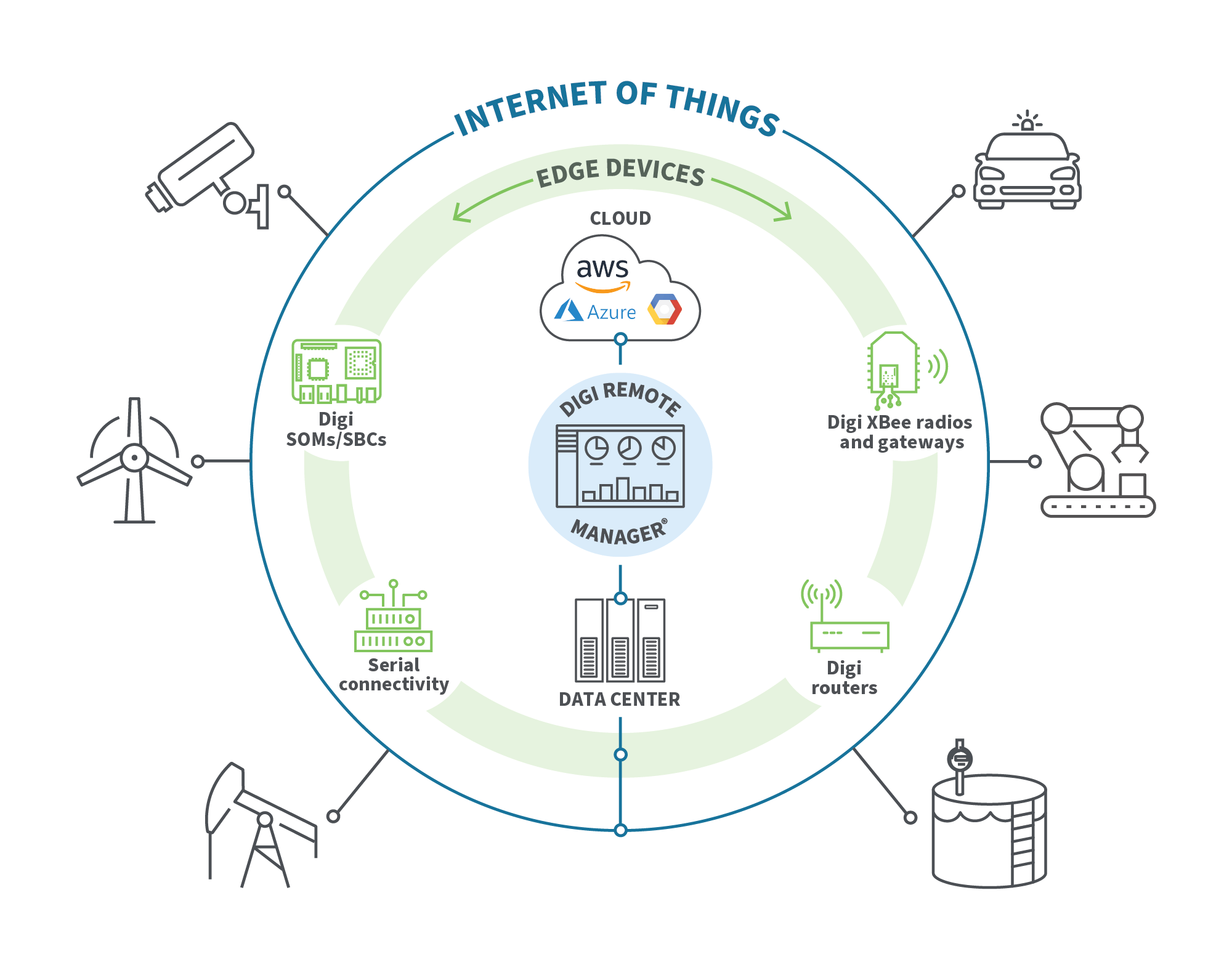
Systèmes Edge
Les systèmes de périphérie sont des solutions complètes qui fournissent aux organisations tous les composants nécessaires pour traiter les données à la périphérie. En général, il y a quatre composants principaux : les appareils mobiles et IoT , la connectivité réseau, les solutions de stockage et les plates-formes de gestion du système. Les appareils collectent et traitent les données à la périphérie, tandis que les réseaux permettent de transmettre les données désignées aux solutions de stockage, telles que les serveurs ou le stockage en nuage. Les plateformes de gestion des systèmes assurent la supervision du système périphérique, en surveillant les appareils, les vitesses de connexion, etc.
Voici quelques exemples de systèmes Digi edge :
Dispositifs de bord
Les dispositifs de périphérie sont des solutions matérielles informatiques spécialisées qui prennent en charge le traitement des données à la périphérie. En outre, ils peuvent répondre à divers besoins en matière de connectivité, garantissant que toute transmission de données qui doit avoir lieu le soit avec un temps de latence limité et une fiabilité appropriée. Parmi les dispositifs de périphérie les plus courants, on peut citer
Plateformes de pointe
L'informatique en périphérie nécessite des plateformes logicielles pour soutenir et gérer l'ensemble du système. Digi Remote Manager est un exemple de solution complète. Avec Digi Remote Manager, la configuration et le déploiement des appareils sont centralisés. En outre, les organisations peuvent mettre en place des mises à jour automatiques des appareils, surveiller la sécurité et recevoir des alertes instantanées. Des options de sécurité avancées sont également disponibles, telles que le VPN.
- Digi Remote Manager
- Microsoft Azure IoT Edge
- Google Distributed Cloud Edge
Produits et services d'informatique de pointe
Digi est l'un des principaux fournisseurs de produits et de services d'informatique de pointe, offrant des solutions de haute performance adaptées à des secteurs spécifiques. Ces solutions complètes fournissent les appareils critiques, les logiciels et les services de soutien dont les organisations ont besoin pour passer à l'infrastructure de périphérie en toute transparence.
Voici un aperçu des différents produits et services Digi Edge Computing et de la manière dont ils peuvent bénéficier à votre organisation.
Matériel informatique de pointe
Les solutions matérielles Edge Computing de Digi sont conçues pour répondre aux besoins des organisations qui cherchent à tirer le meilleur parti de leur investissement IoT , en s'assurant qu'elles disposent de la capacité de calcul, de la sécurité et d'une connectivité fiable pour rationaliser les opérations, améliorer la sécurité, automatiser les processus et prendre en charge des capacités avancées telles que l'intelligence artificielle. Des systèmes embarqués aux routeurs cellulaires, les solutions Digi permettent un edge computing avancé dans tous les secteurs d'activité. Il s'agit notamment de :

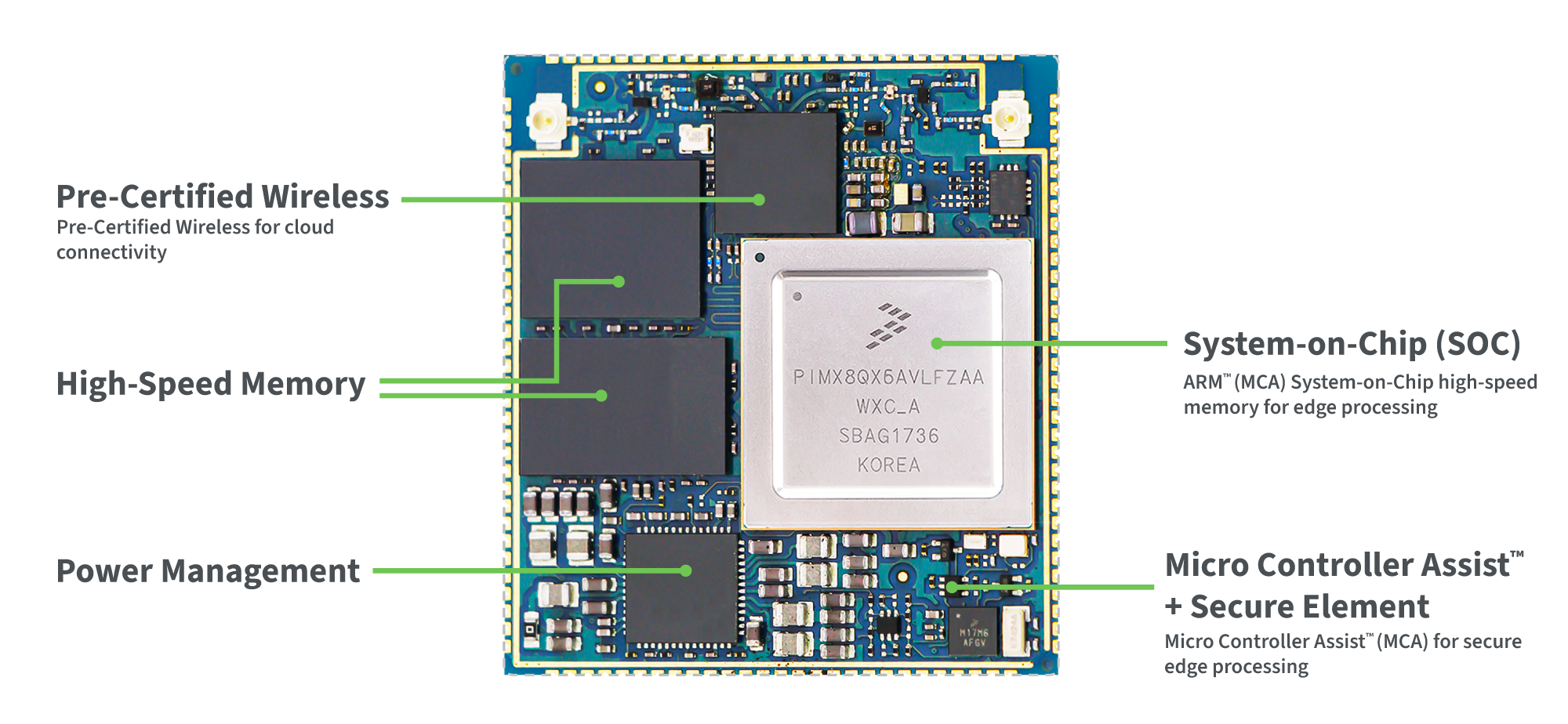
Puces de bordure
Les puces Edge sont des composants intégrés dans des systèmes sur modules, conçus pour répondre aux exigences les plus avancées des applications IoT dans les domaines de la médecine, de l'industrie et des transports. Ces SOM prennent en charge l'IA à la périphérie, améliorant les capacités des appareils de périphérie et prenant en charge l'analyse des données en temps réel pour une prise de décision rapide et des ajustements opérationnels. Digi intègre les processeurs d'application les plus puissants de l'industrie provenant de fabricants tels que NXP et STMicroelectronics, avec des solutions prêtes à être conçues qui permettent aux organisations de tout secteur de bénéficier de ces technologies de pointe avec un délai de mise sur le marché rapide.
Serveurs Edge
Les serveurs périphériques existent en dehors du centre de données central ou de la solution en nuage, ce qui les rapproche des utilisateurs finaux et des appareils générateurs de données. L'intégration de serveurs périphériques augmente la capacité de calcul tout en réduisant considérablement le temps de latence. En outre, les serveurs périphériques sont connectés aux réseaux internes, ce qui élimine le besoin de transférer des données sur Internet et les rend plus sûrs.
Digi offre une gamme d'options de serveur conçues pour répondre à une variété de besoins et de cas d'utilisation, y compris :
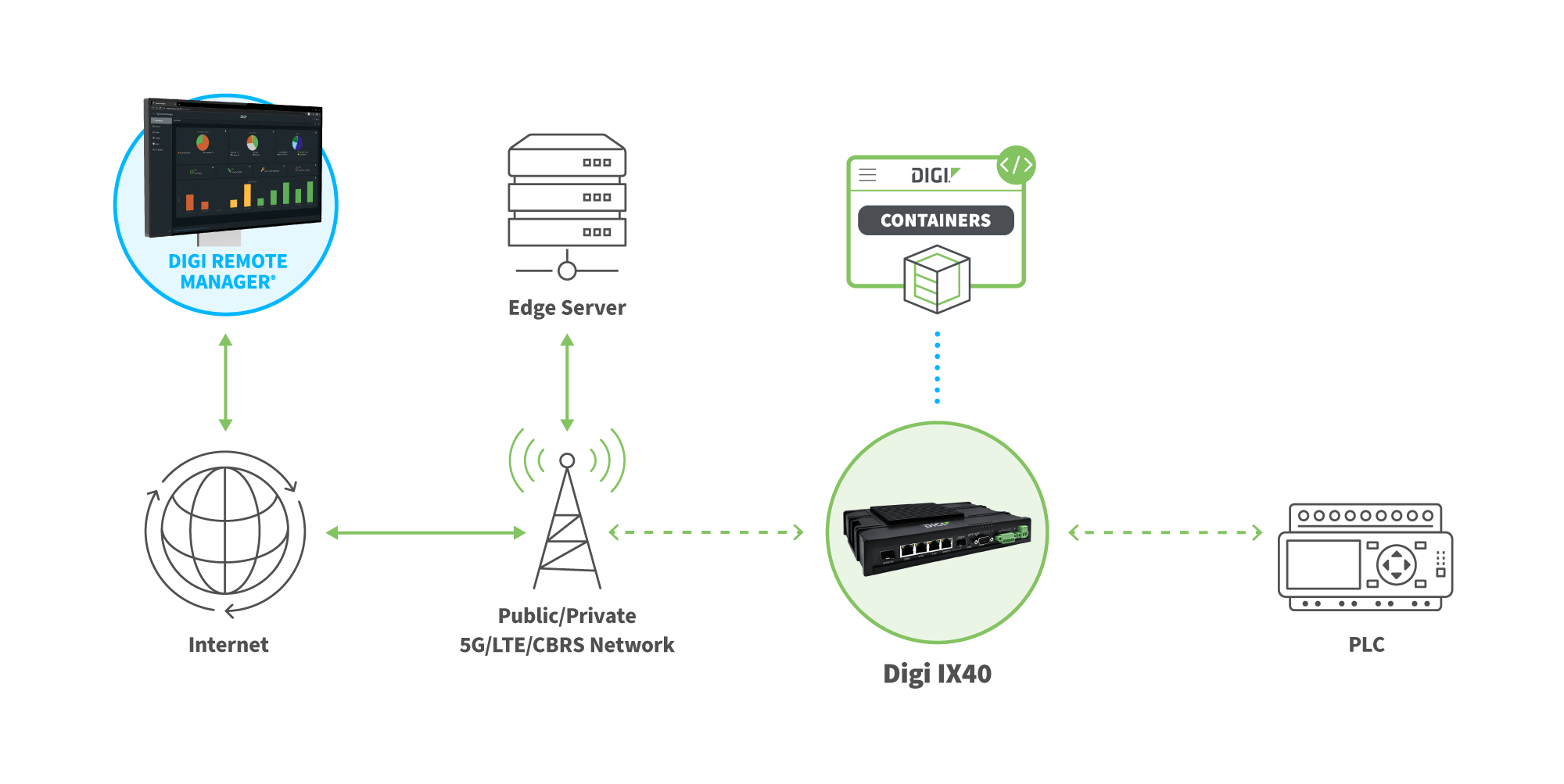
Nœuds d'informatique en périphérie
Les nœuds informatiques périphériques sont des machines physiques ou virtuelles placées à la périphérie d'un réseau et comprennent la gamme d'appareils et de serveurs périphériques dont nous avons parlé. Ils fonctionnent généralement comme des routeurs, des passerelles, des processeurs d'application ou des serveurs de périphérie, permettant aux appareils IoT de communiquer entre les réseaux, d'effectuer des tâches de périphérie (dans le cas des appareils intelligents) et de transférer des données vers et depuis d'autres appareils de périphérie ou un serveur de périphérie intermédiaire connecté au nuage. En outre, ils peuvent potentiellement contribuer à la collecte et à l'analyse des données, ainsi qu'à l'exécution d'applications conteneurisées avec lesquelles les appareils IoT doivent interagir dans le cadre de leurs activités.
Les nœuds de calcul de périphérie de Digi - qui comprennent tous les dispositifs matériels de périphérie énumérés ci-dessus - sont des solutions flexibles, programmables, faciles à déployer et à gérer, qui peuvent être configurées pour répondre aux besoins d'une vaste gamme d'applications de calcul de périphérie. En outre, nos solutions donnent la priorité à la sécurité, garantissant ainsi la protection de votre environnement.
Logiciel d'informatique de pointe
Le logiciel Edge Computing simplifie la gestion d'un réseau intelligent. En plus d'assurer la supervision, Digi Remote Manager rationalise la configuration et le déploiement des appareils. De plus, il prend en charge les mises à jour de masse des micrologiciels et des logiciels tout au long du cycle de vie du produit afin de simplifier la sécurité et la conformité, tout en fournissant des alertes en temps réel sur l'état des appareils et la santé du réseau.
Services d'informatique de pointe
IoT et l'informatique de pointe offrent d'énormes avantages aux organisations qui cherchent aujourd'hui à utiliser au mieux leurs effectifs, leurs ressources et leurs budgets pour optimiser leurs opérations, leurs services informatiques et techniques et leur sécurité. Mais la mise en œuvre de ces initiatives peut ajouter de la complexité aux objectifs de l'organisation lors de la planification, du développement et du déploiement, ainsi que de la gestion continue de ce déploiement.
Digi dispose d'une gamme complète de services pour soutenir les initiatives des organisations dans tous les secteurs, qu'il s'agisse de concevoir et de construire des produits avec des systèmes intégrés, de déployer IoT et des dispositifs informatiques à la périphérie du réseau, ou de mettre à niveau leur infrastructure existante pour améliorer leurs opérations :
- Services de conception Digi Wireless: Cette équipe d'ingénieurs très talentueux peut aider les OEM à réaliser des prototypes, à développer, à certifier, à gérer et à commercialiser des produits.
- Services professionnels Digi: Cette équipe d'experts peut vous fournir une large gamme d'assistance lors de la planification de votre déploiement, depuis les études de site jusqu'à l'approvisionnement et le déploiement, en passant par l'écriture de scripts et la programmation, et le soutien à la gestion continue de votre réseau déployé.
- Services de connectivité Digi: L'équipe Digi Connectivity Services aide les OEM qui développent des produits avec des modules Digi XBee Cellular à mettre rapidement en place des plans de données, ce qui rend le processus d'ajout de connectivité cellulaire et de construction de réseaux sans fil simple et pratique.
- Support technique Digi: Cette équipe de professionnels peut aider au dépannage technique et à la résolution des problèmes grâce à une gamme d'options d'assistance, y compris des contrats d'assistance prioritaire pour les déploiements critiques.
Digi International : Leaders en matière de solutions d'Edge Computing
À l'ère du numérique, les solutions d'informatique de pointe offrent des fonctionnalités essentielles tout en rationalisant les opérations. Le traitement des données à la source permet l'automatisation, l'analyse en temps réel et la prise de décision rapide dans des environnements en constante évolution. En fin de compte, les systèmes de périphérie garantissent une agilité et une évolutivité permanentes, tout en améliorant la puissance de calcul et en facilitant l'intégration et le déploiement de technologies de pointe telles que l'IA et l'apprentissage automatique.
Digi fournit des solutions de pointe conçues pour répondre aux besoins d'un large éventail d'industries, de l'automatisation de la fabrication aux soins de santé, à la vente au détail, au transport, au secteur public et plus encore. Nos solutions sont conçues dans un souci de robustesse et de conformité, ce qui leur permet de fonctionner de manière optimale dans des conditions difficiles et de fournir des mécanismes de sécurité essentiels pour protéger les données.